Abstract
We present VGGT, a feed-forward neural network that directly infers all key 3D attributes of a scene, including camera parameters, point maps, depth maps, and 3D point tracks, from one, a few, or hundreds of its views. This approach is a step forward in 3D computer vision, where models have typically been constrained to and specialized for single tasks. It is also simple and efficient, reconstructing images in under one second, and still outperforming alternatives without their post-processing utilizing visual geometry optimization techniques. The network achieves state-of-the-art results in multiple 3D tasks, including camera parameter estimation, multi-view depth estimation, dense point cloud reconstruction, and point tracking. We also show that using pretrained VGGT as a feature backbone significantly enhances downstream tasks, such as non-rigid point tracking and feed-forward novel view synthesis.
Method
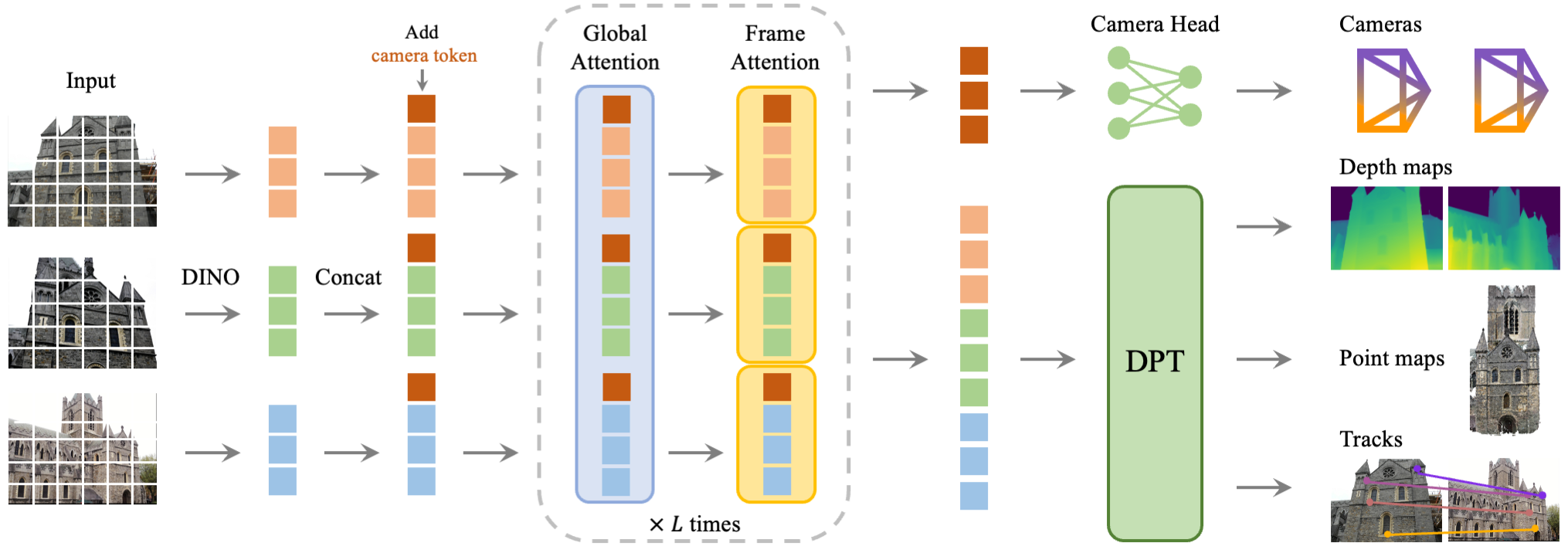
VGGT first patchifies the input images into tokens by DINO, and appends camera tokens for camera prediction. It then alternates between frame-wise and global self attention layers. A camera head makes the final prediction for camera extrinsics and intrinsics, while a DPT head for any dense output, such as depth maps, point maps, or feature maps for tracking.
Qualitative Visualization
Reconstruction of In-the-wild Photos/Videos with VGGT. Click on any thumbnail below to view the 3D reconstruction.


Qualitative Comparison
VGGT significantly outperforms all other methods across various tasks. Please refer to our paper for quantitative results. Here we also provide a qualitative comparison with DUSt3R and other concurrent works such as Fast3R and FLARE (use the dropdown menu to switch).

